最近在弄這個專案,純粹是因為幾個月前去台南玩的時候,逛街逛著想要找間便利商店,有種感覺-便利商店好像比新竹少?在新竹市街上走著,好像很容易就看到便利商店。
要來驗證這種主觀的感覺是否為真,就得要有充分的數據來支持。
首先得先找到超商的資料庫,在政府開放資料平臺上,有一個全國5大超商資料集,剛好可以用來解答。
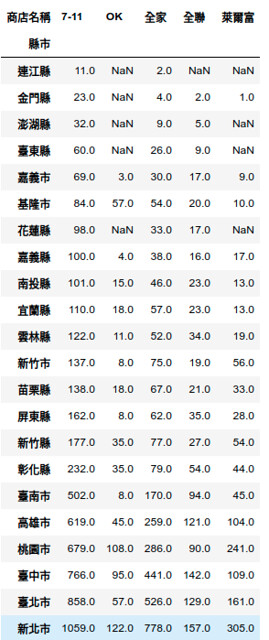
不過我熟悉的就只有四大超商而已,哪來五大呢?看了資料集才知道它是連全聯一起算進去啊。
有了這個資料集,可以先作一些簡單的探索性分析,像是各縣市的五大超商數量。
- 新北、台北是第一名和第二名
- 小七在各縣市都是最多的,接下來就是全家
- 在某些縣市是沒有OK、萊爾富、全聯等便利商店

在五大超商資料集中,還有各分公司的地址,既然有地址,就可以拿來作地理資訊分析了。不過地址怎麼轉成經緯度呢?有兩種作法,一是用
Google Maps API,不過有一些數量和時間的限制,所以我改用方法二。
方法二就是用
地理資訊圖資雲服務平台,平台有一個「全國門牌地址定位服務」,只要成為TGOS會員,一天可以比對一萬筆的資料。會員的申請不用錢,比對資料也不用錢,真是太棒了。
會員申請好了以後,再申請[ 批次門牌地址比對服務 ] ,就可拿到一組認證金鑰(API KEY)。申請會員和申請地址比對服務大概都是人工作業,所以不是隨時申請就隨時通過的,但上班時間內幾個小時內就會通過。然後地址轉經緯度也不用寫程式去呼叫,只要上傳你的地址csv檔之後,過一段時間,系統就會通知你去下載結果。
由於我使用的超商資料接近兩萬筆,所以我就分兩天去轉經緯度,但不是每一個地址都有順利轉出來的,大約三百多筆資料沒轉出來,比較多是因為該超商的地址有多個門牌號碼,而系統只能比對一個門牌。我評估三百多筆資料的缺失,對我的分析作業影響不大,所以我就不管那些呢。
第一張圖並不區分超商的公司為何,沒想到完全可以勾勒出台灣的位置。但是啊,仔細看會發現怎麼台灣西北方會出現一些超商的點啊?這個應該是轉門牌為經緯度的時候,有些點位的誤差。

另外一張圖將不同公司用不同顏色標上去,乍看之下到處都是全聯,但其實是因為全聯是繪圖時最後一組被標上的,所以它把其他超商蓋過去了。
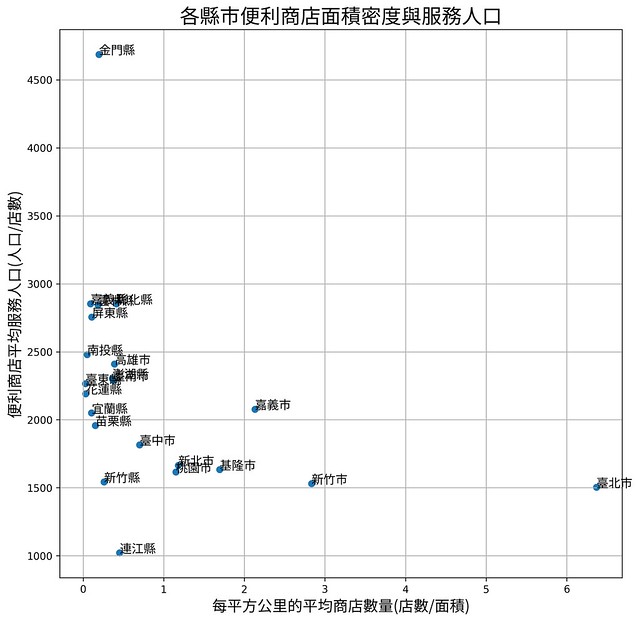
接下來就開始用內政部的其他資料一起來畫圖吧,找了各縣市的人口和面積,然後計算兩個指標
- 該縣市的人口/除以該縣市的便利商店店數,這當作是一個店的服務人口。那為什麼不用店數/人口呢?可以看一個人可以有幾家店呢?是可以啦,但是會一堆小數點,不是那麼直觀。
- 該縣市的商店數/該縣市的面積,這個就便利商店的面積密度。
用這兩個指標畫圖以後,喔,就看到呈現兩種趨勢,大多數的縣市在每一平方公里的商店數量大致相同,但是幾個縣市如台北、新竹、嘉義、基隆等就比別的縣市多。服務人口的部份,金門縣的單店服務人口就很多。
但仔細想想用面積密度來算,可能會有一些缺失,比方說某縣市可能有很大的郊區,例如很大的山區如陽明山,或是很大的水庫,而這些地方本來就沒有什麼便利商店啊。所以在分析時,這種郊區的存在就可以能造成分析的偏差。
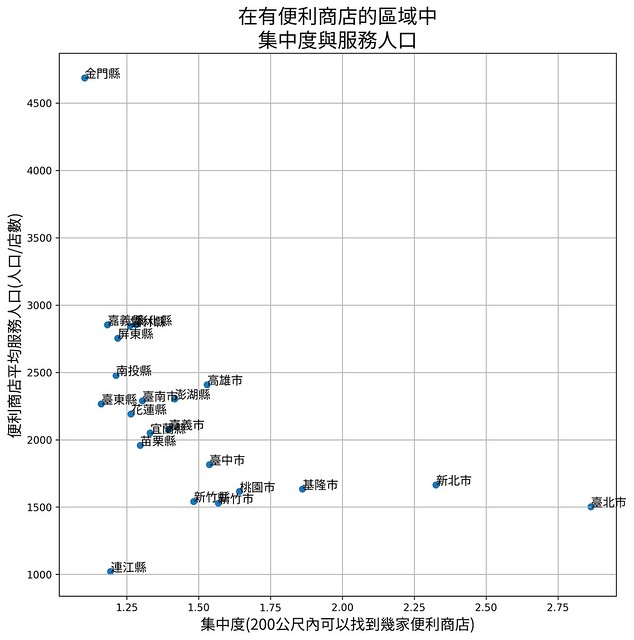
怎麼辦呢?我改用另一種方式來分析,改用「在有便利商店的區域中,你在兩百公尺內可以找到幾家便利商店」來分析吧!我用下圖作範例來說明一下吧。
假設以下三個縣市都有三個便利商店(淺藍色的點),而三個縣市的形狀剛好都是正方形,所以我們計算三個縣市的商店密度,都會得到相同的數值。
但如果我們把每個商店周圍都劃一個圓圈,代表這個商店的勢力範圍(灰圈圈),然後把每個商店的勢力範圍取聯集。我們就可以用這個方式去計算出在這個聯集的勢力範圍內,你可以遇到幾家便利商店。這代表的意義是什麼呢?
如果是左邊第一個縣市,它的商店就是很分散,你到了一家便利商店之後,附近200公尺內就沒有其他便利商店了。但右邊的商店就很集中,到處都看得到便利商店。

改用這種指標之後,再來畫個圖,這時就會發現又不一樣囉。新竹無論縣市,在便利商店的區域中,你很容易就找到另一家便利商店。但有些縣市就不是這樣。
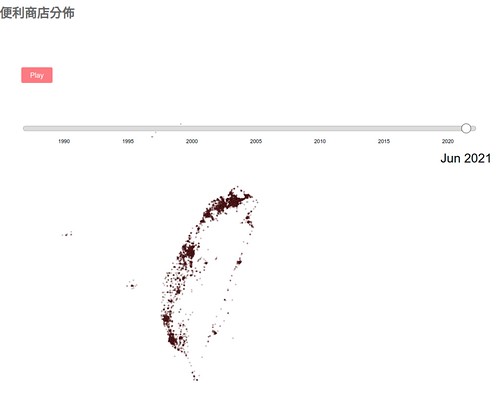
作完了這兩張圖之後,其實心裡還想到很多分析的變項,像是便利商店的多寡一定是跟人口數量有關,所以如果拿人口再來作圖會變成怎樣呢?想來想去,覺得光是用2維的靜態圖表來呈現實在不夠,所以就在用D3來做動態圖表吧
你可以在以下網址自由改變不同的 X軸和 Y軸,看看這些變項與便利商店的關係
以下貼幾個範例,這是觀察面積和人口的關係,左上角的「縣市標籤」勾選後,會出現縣市名稱,另外滑鼠靠近資料點,也會呈現該資料點的各種屬性數值。
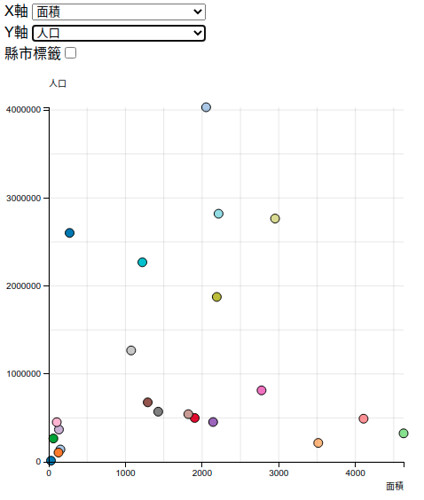
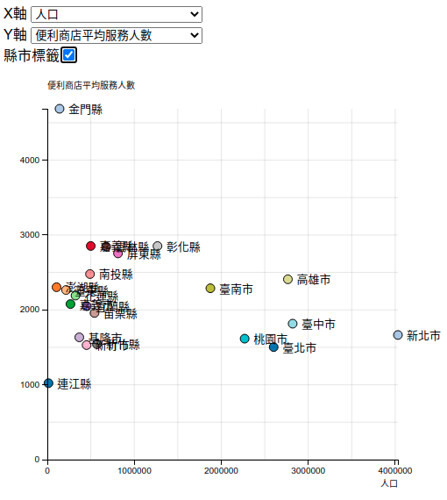
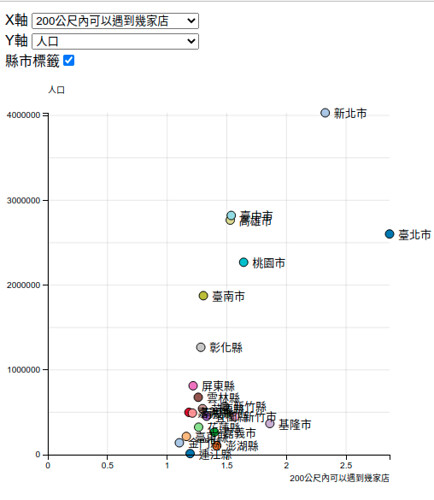
本來想說做完這個動態的散佈圖應該就可以結束了吧,但是某天早上醒來,想想好像可以作一個隨著時間變化,便利商店在各地的增長。所以我又做了一個動態圖表
拖曳那個時間軸,可以看到各地的便利商店的變化
不過喔,一直有bug,因為一次是畫了一萬多個點上去,所以每次調整時間軸,都有一些便利商店的點沒有被畫上去,特別是按那個「play」,會看到便利商店變稀疏。如果要比較真實呈現的話,也不要用slider在那邊滑,你就直接點時間軸的特定位置,畫出來的還比較準確哩。